はじめに
本記事では、オープンソースのLLM(大規模言語モデル)であるDeepSeek-R1を使用して、一般的なWindowsノートPC上でChatGPT風のアプリケーションを実装した検証結果を共有します。
本記事作成に当たっては、Cursor・VSCodeの機能拡張Clineによるコード自動生成、記事の自動作成を行っております。DeepSeekモデルの入手から各種コマンド発行、問題解決に至るまで絶大な効果を発揮しました。Clineさんいつもありがとうございます。
下記がDeepSeek-R1の軽量モデルと会話やり取りするためのwebアプリケーションです。
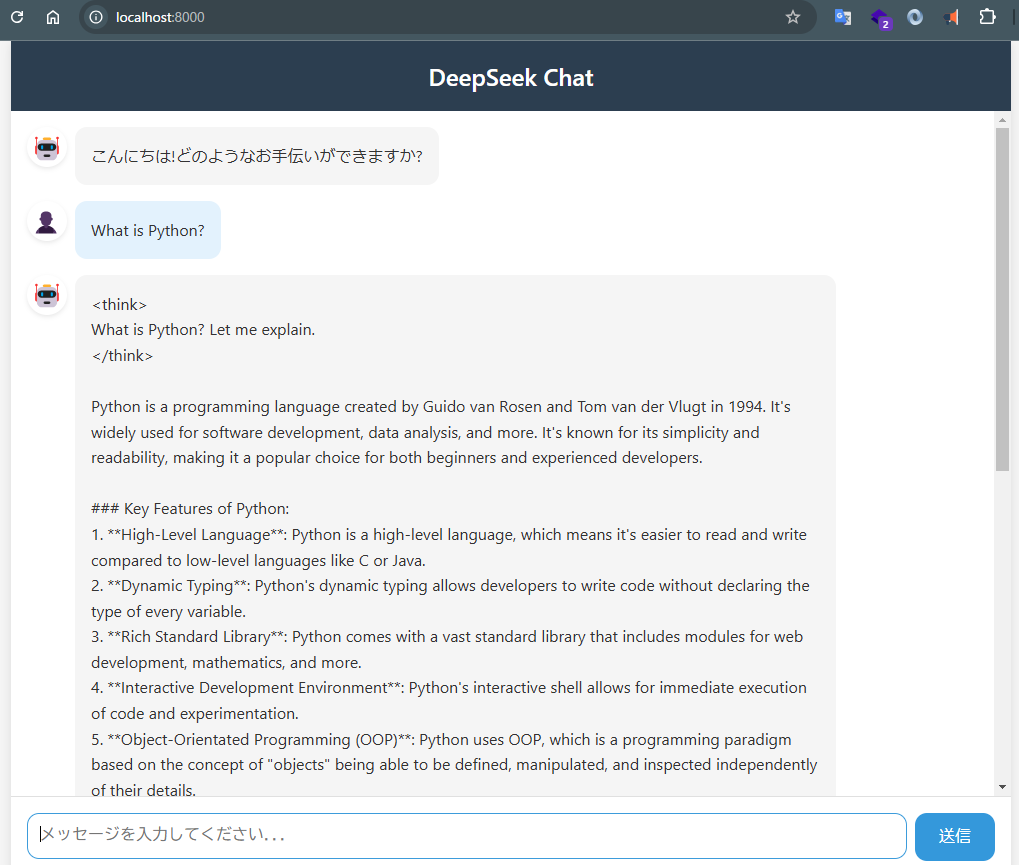
以下ローカルPCで動作させてみた所感です。
- 質問から返答を受け取るまでは数分程度は時間がかかることを確認
- その間PC上のCPU利用率、メモリ使用状況が上昇し、ファンが回ってPCが苦しそうな状況を確認
- 「What is Python?」「What is database?」など技術的な質問のほうが得意な傾向を確認
- 日本語で質問をするとオウム返しをしたり、同じフレーズを繰り返したりあまりうまく動作をしないことを確認
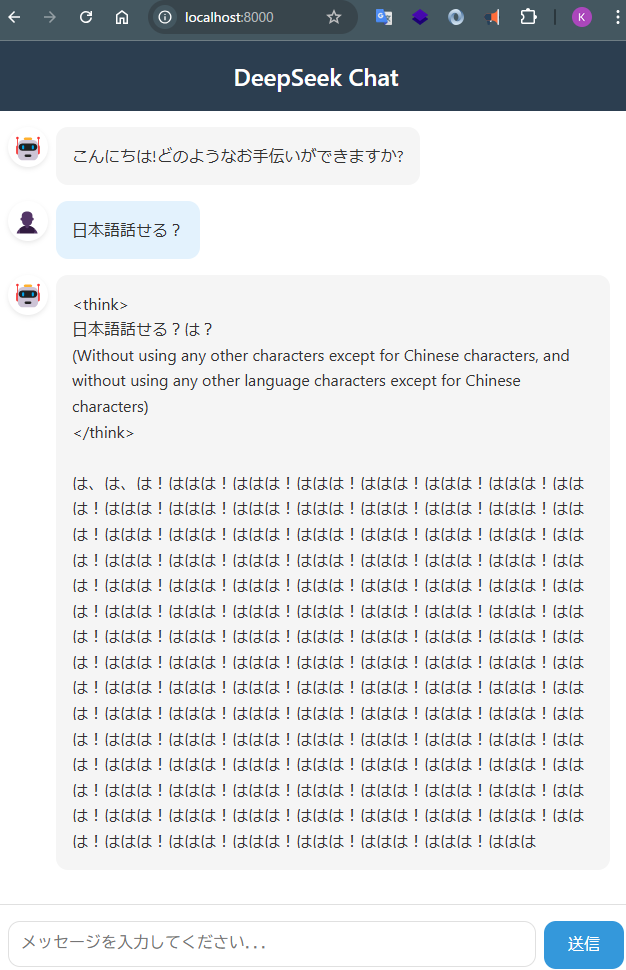
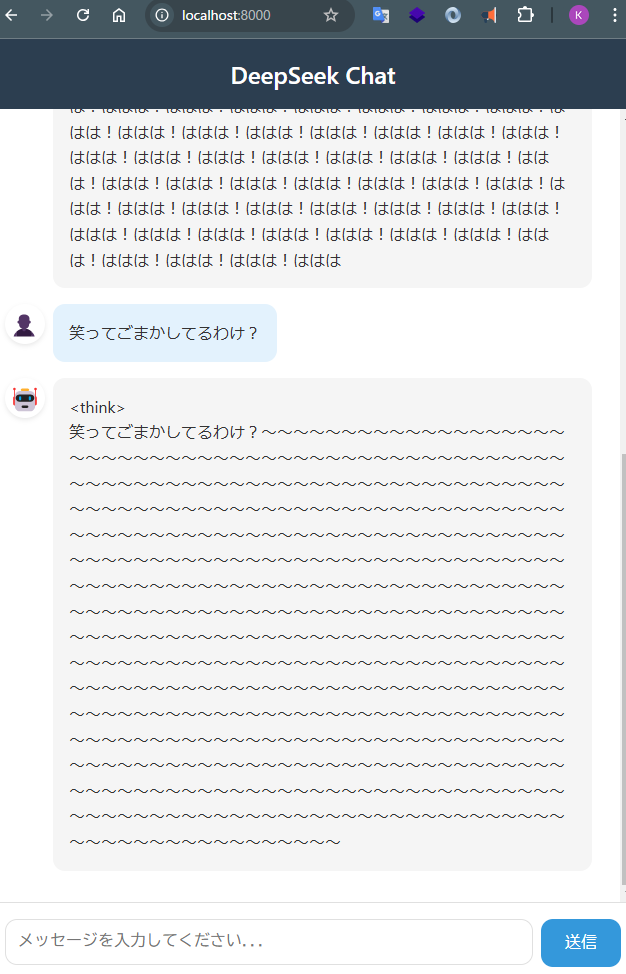
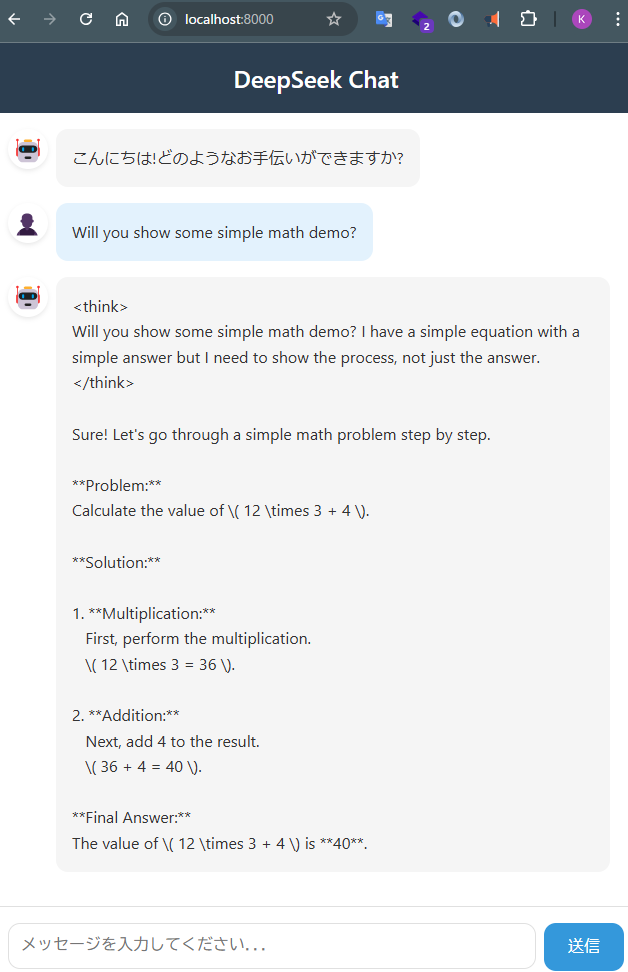
- 「Will you show some simple math demo?」についてもまともな結果を返せることを確認
検証の目的
- ローカル環境での実行可能性
- GPUを搭載していない一般的なWindowsノートPCでも、LLMベースのアプリケーションが実行可能かを検証
- 特別なハードウェアでなくても起動ができそうな軽量モデル(DeepSeek-R1-Distill-Qwen-1.5B)の動作状況を検証
- オープンソースLLMの活用
- オープンソースモデルによる実装
- ネット接続不要で、完全にローカルで動作する環境の構築
DeepSeek-R1-Distill-Qwen-1.5Bのライセンス
このモデルは以下のライセンスの下で提供されています:
- DeepSeek-R1シリーズ全体: MITライセンス
- 商用利用可能で、改変や再配布も許可
- 再配布時にはライセンス表示が必要
1. DeepSeekのリポジトリクローン
まず、GitHubからDeepSeekのリポジトリをクローンします:
git clone https://github.com/deepseek-ai/DeepSeek-R1.git
2. モデルの選択
DeepSeekには大型モデルのDeepSeek-R1とDeepSeek-R1-Zeroに加え以下のモデルが用意されています:
| モデル名 | パラメータ数 | 特徴 |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | 軽量・高速 |
| DeepSeek-R1-Distill-Qwen-7B | 7B | バランス型 |
| DeepSeek-R1-Distill-Qwen-14B | 14B | 高性能 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 最高性能 |
| DeepSeek-R1-Distill-Llama-8B | 8B | Llama系 |
| DeepSeek-R1-Distill-Llama-70B | 70B | 最大モデル |
今回は何でも良いので軽量でノートPCで起動を試みたいとの理由からDeepSeek-R1-Distill-Qwen-1.5Bを選択しました
3. モデルの取得とシステム要件
3.1 モデルの取得プロセス
DeepSeekのモデルは以下のプロセスで取得されます:
- GitHubリポジトリのクローン
- このリポジトリにはモデルの実装コードやドキュメントが含まれています
- 実際のモデルの重みファイルは含まれていません
- Hugging Face Hubからのモデルダウンロード
- モデルの重みファイルはHugging Face Hubで公開されています
- transformersライブラリが自動的にモデルをダウンロードします
from transformers import AutoModelForCausalLM, AutoTokenizer
# 初回実行時に自動的にモデルがダウンロードされます
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
ダウンロードされたモデルは ~/.cache/huggingface/hub に保存されます
- キャッシュの活用
- 2回目以降の実行時は、ローカルにキャッシュされたモデルが使用されます
- インターネット接続は初回のダウンロード時のみ必要です
3.2 システム要件
基本要件
- Python 3.8以上
- CUDA対応GPUを推奨(CPU実行も可能)
- 最小メモリ要件:
- DeepSeek-R1-Distill-Qwen-1.5B: 8GB以上
今回の検証に用いた環境
- ホストOS: Windows 11 Enterprise
- 実行環境: WSL2 (Windows Subsystem for Linux 2)
- ハードウェア:
- CPU: Intel 64ビットプロセッサ
- メモリ: 16GB
- 実行モード: CPUモード(GPUなし)
- メモリ使用量を考慮して
max_length=512に設定しています - GPUがなくてもCPUモードで動作可能ですが、応答生成に時間がかかる場合があります
3.2 環境構築
必要なPythonパッケージをインストールします:
pip install fastapi uvicorn jinja2 transformers torch
4. アプリケーションの構成
4.1 プロジェクト構造
プロジェクトは以下のような最小限の構造になっています:
.
├── .gitignore # Git除外設定
├── DeepSeek_setup_guide.md # 技術ドキュメント
└── src/
├── README.md # ソースコードの説明
├── models/
│ ├── check_model.py # モデル動作確認
│ └── inference.py # モデル推論実装
└── web/
├── app.py # FastAPIアプリケーション
├── static/
│ ├── script.js # フロントエンド処理
│ └── style.css # スタイル定義
└── templates/
└── index.html # メインページ
この構造は、必要最小限のファイルのみを含み、以下の特徴があります:
- モデル関連 (
src/models/)inference.py: モデルの推論処理の中核check_model.py: モデルの動作確認用ユーティリティ
- Webアプリケーション (
src/web/)app.py: FastAPIベースのバックエンドstatic/: フロントエンドのアセットtemplates/: HTMLテンプレート
- ドキュメント
DeepSeek_setup_guide.md: 包括的な技術ドキュメントsrc/README.md: ソースコードの説明
4.2 モデル推論設定 (inference.py)
主な設定パラメータ:
# モデル選択
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
# デバイス設定
use_gpu = False # CPUモードで実行する場合はFalse、GPUを使用する場合はTrue
# 生成パラメータ
max_length = 512 # 最大生成トークン数(メモリ使用量とのバランスを考慮)
temperature = 0.6 # 生成の多様性(0.5-0.7推奨)
top_p = 0.95 # サンプリングの閾値
CPU/GPUモードの切り替え
モデルはCPUモードとGPUモードの両方で実行可能です:
def load_model(use_gpu=False):
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# GPUが利用可能で、use_gpuがTrueの場合はGPUを使用
device = "cuda" if use_gpu and torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
print(f"Model loaded on: {device}")
return model, tokenizer
- CPUモード: GPUが不要で、一般的なコンピュータでも実行可能です。ただし、推論速度は比較的遅くなります。
- GPUモード: CUDA対応のNVIDIA GPUが必要ですが、高速な推論が可能です。
デフォルトではCPUモードで動作します。GPUモードを使用する場合は、load_model(use_gpu=True)と設定してください。
4.3 Webアプリケーション実装
FastAPIアプリケーション (app.py)
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
from fastapi.staticfiles import StaticFiles
from fastapi.responses import JSONResponse
app = FastAPI()
# 静的ファイルとテンプレートの設定
app.mount("/static", StaticFiles(directory="src/web/static"), name="static")
templates = Jinja2Templates(directory="src/web/templates")
# ルート設定
@app.get("/")
async def read_root(request: Request):
return templates.TemplateResponse("index.html", {"request": request})
# チャットエンドポイント
@app.post("/chat")
async def chat(request: Request):
data = await request.json()
user_input = data.get("message", "")
response = generate_response(model, tokenizer, user_input)
return JSONResponse({"response": response})
フロントエンド実装 (index.html)
<!DOCTYPE html>
<html>
<head>
<title>DeepSeek Chat Interface</title>
<link rel="stylesheet" href="/static/style.css">
</head>
<body>
<div class="chat-container">
<div id="chat-messages"></div>
<div class="input-container">
<input type="text" id="user-input" placeholder="メッセージを入力...">
<button onclick="sendMessage()">送信</button>
</div>
</div>
<script src="/static/script.js"></script>
</body>
</html>
スタイル設定 (style.css)
.chat-container {
max-width: 800px;
margin: 0 auto;
padding: 20px;
}
.chat-message {
margin: 10px 0;
padding: 10px;
border-radius: 5px;
}
.user-message {
background-color: #e3f2fd;
text-align: right;
}
.assistant-message {
background-color: #f5f5f5;
}
.input-container {
display: flex;
gap: 10px;
margin-top: 20px;
}
#user-input {
flex: 1;
padding: 10px;
}
クライアントサイドロジック (script.js)
async function sendMessage() {
const input = document.getElementById('user-input');
const message = input.value.trim();
if (!message) return;
// メッセージを表示
addMessage('user', message);
input.value = '';
try {
const response = await fetch('/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ message: message }),
});
const data = await response.json();
addMessage('assistant', data.response);
} catch (error) {
console.error('Error:', error);
addMessage('assistant', 'エラーが発生しました。');
}
}
function addMessage(type, content) {
const messagesDiv = document.getElementById('chat-messages');
const messageDiv = document.createElement('div');
messageDiv.className = `chat-message ${type}-message`;
messageDiv.textContent = content;
messagesDiv.appendChild(messageDiv);
messagesDiv.scrollTop = messagesDiv.scrollHeight;
}
5. アプリケーションの起動
以下のコマンドでWebアプリケーションを起動します:
python src/web/app.py
アプリケーションは http://localhost:8000 で利用可能になります。
6. モデル使用上のポイント・Tips
- システムプロンプトは使用せず、ユーザープロンプトに全ての指示を含める
- 数学的問題の場合は “Please reason step by step, and put your final answer within
\boxed{}” を含めることを推奨 - 思考パターンを強制するため、出力を “
<think>\n” で開始することを推奨
7. 今後の可能性
今回の検証では、ビジネス用ノートPC上でCPUモードでの動作を確認しましたが、以下の改善の余地があります:
GPU環境での性能向上
- 推論速度の大幅な改善
- NVIDIA GPUを搭載したPCでの実行により、応答速度が数倍から数十倍に改善
- バッチ処理の最適化による並列処理の効率化
- モデルサイズの拡張
- より大きなモデル(7B、14B)の使用が現実的に
- 応答品質や日本語能力の向上が期待できる
- チューニングの可能性
- 量子化(8bit、4bit)による効率化
- モデルパラメータの最適化
- プロンプトエンジニアリングの改善
カスタマイズと拡張性
- オープンソースの利点
- ソースコードとモデルの完全な可視性
- MITライセンス/Apache 2.0ライセンスによる自由な改変が可能
- 商用利用を含む幅広い用途での活用が可能
- モデルのカスタマイズ
- 特定ドメイン向けの追加学習が可能
- タスク特化型のファインチューニング
- 日本語能力強化のための最適化
- 用途に応じた最適化
- 業務特性に合わせたプロンプト設計
- レスポンス生成パラメータの調整
- モデルの軽量化や効率化
検証の意義
本検証では、特別なハードウェアを必要としない最小構成での動作を確認しました。これを基盤として、GPU環境での最適化やチューニングに加え、オープンソースの特性を活かしたカスタマイズや追加学習を行うことで、より実用的で特化したアプリケーションの開発が可能になると考えられます。